Czym jest uptime i jak się to ma do czasu przestoju? Ile dziewiątek po przecinku gwarantuje względny spokój, gdy mowa jest o wysokiej dostępności infrastruktury informatycznej? I na koniec, na co postawić: na nadmiarowość, czy może na błyskawiczne odtwarzanie po awarii?
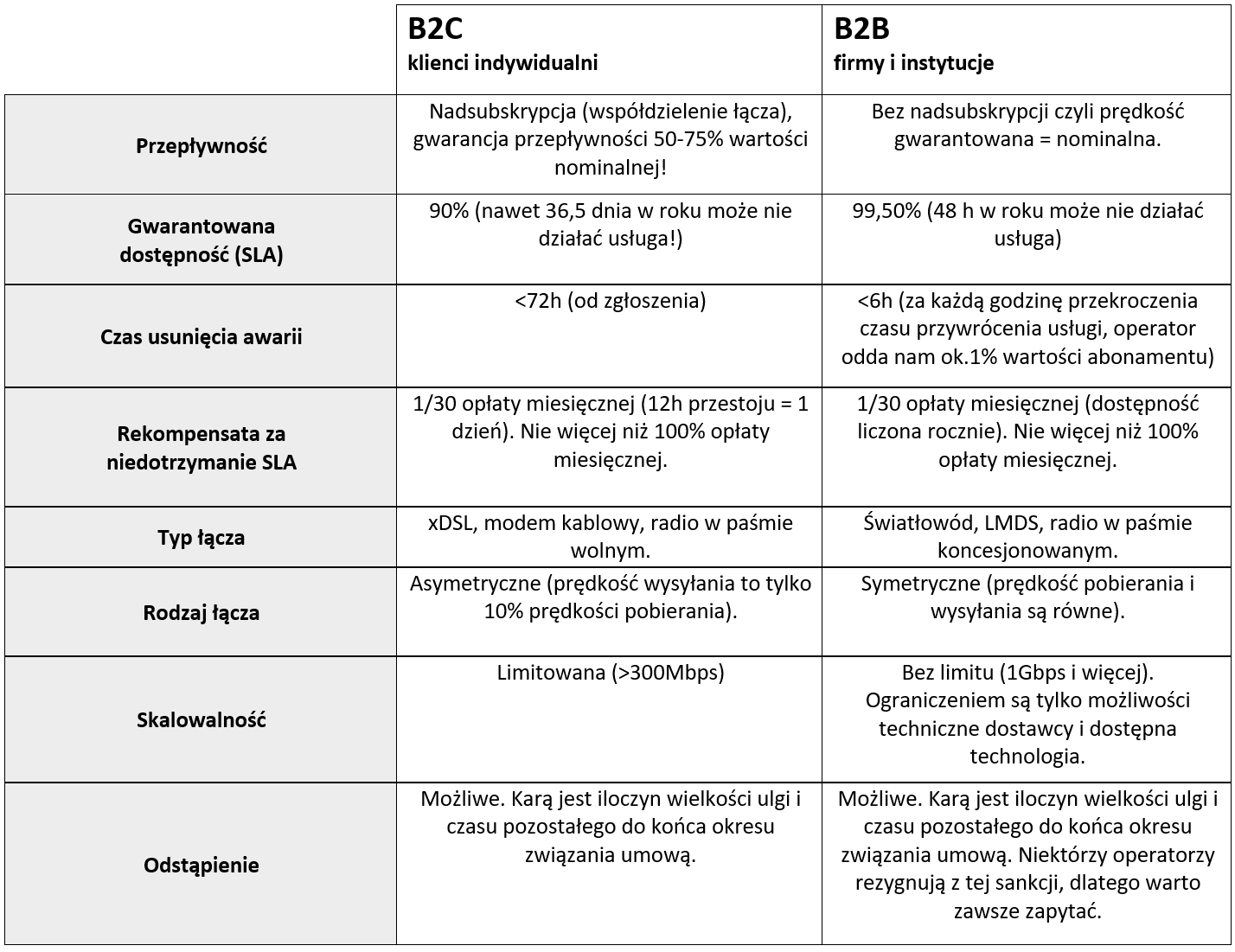
Czy wiesz jaki poziom dostępności mają Twoje systemy? Najlepsze centra danych w Polsce (np.: Atman, Beyond, Exea, Polcom, T-mobile), mogą pochwalić się niezawodnością na poziomie 99,99%. Oznacza to, że ich przestój w skali roku nie przekroczy godziny. Zwracam jednak uwagę, że procenty dotyczą określonych usług. Już tłumaczę. Powiedzmy, że zdecydujemy się na usługę kolokacji, czyli wynajmujemy miejsce w szafach teletechnicznych w centrum danych. Usługodawca deklaruje cztery dziewiątki. Czy w związku z tym nasze środowisko także będzie miało dostępność na poziomie 99,99%? Najprawdopodobniej nie. Wysoka dostępność dotyczy systemów zbudowanych w centrum danych, w tym zasilania, łączności, klimatyzacji, itp. Wystarczy, że architektura naszego rozwiązania została zaprojektowana bez nadmiarowości. Czyli do szaf wynajętych w centrum danych włożymy pojedyncze urządzenia. Wówczas niestety, poziom dostępności naszego środowiska IT będzie równy poziomowi dostępności najsłabszego elementu.
Czas nieprzerwanej pracy systemów określany jako uptime, dotyczy każdego elementu infrastruktury IT. Projektując wysokodostępne środowisko IT należy eliminować pojedyncze punkty awarii. Robimy to dublując urządzenia z najniższym przeciętnym uptime. Właściwie, to robimy to dublując wszystko co się da 🙂 Jedyne odstępstwa dotyczą usług, których niedostępność nie zatrzymuje procesów krytycznych dla działalności operacyjnej. W ten sposób istotnie zmniejszamy ryzyko wystąpienia przestojów. Naturalnie, poszczególne systemy nie muszą mieć jednakowego poziomu dostępności. Ustalanie precyzyjnych wskaźników dla każdej usługi wpływa wprost na poziom nakładów na środowisko IT i na rodzaj i koszt Disaster recovery.
Wysoka dostępność (HA) jest pochodną nadmiarowości. Odtwarzanie awaryjne uznać powinniśmy za uzupełnienie HA, bo odpowiada na problemy, których nie rozwiąże nawet rozproszony geograficznie klaster wysokiej dostępności. Disaster recovery (np. DRaaS) to ostatnia deska ratunku, gdy nasze systemy padną ofiarą cyberataku lub co bardziej prawdopodobne, staną się niedostępne przez jakiegoś wirusa szyfrującego. Moje doświadczenia pokazują, że nadmiarowość i odtwarzanie po awarii, które według najlepszych praktyk ITIL powinny być komplementarne, bardzo często rozdziela tytułowe „czy”.